Abstract
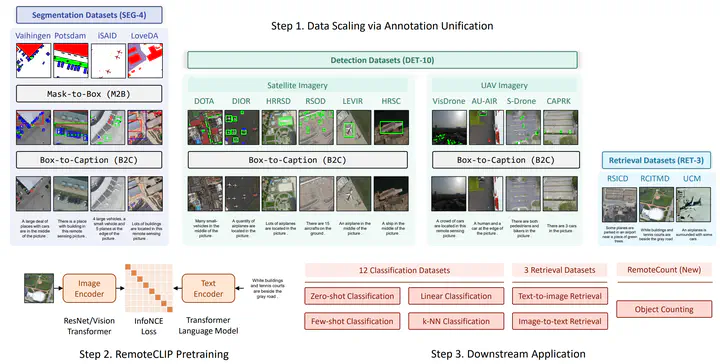
General-purpose foundation models have become increasingly important in the field of artificial intelligence. While self-supervised learning (SSL) and Masked Image Modeling (MIM) have led to promising results in building such foundation models for remote sensing, these models primarily learn low-level features, require annotated data for fine-tuning, and not applicable for retrieval and zero-shot applications due to the lack of language understanding. In response to these limitations, we propose RemoteCLIP, the first vision-language foundation model for remote sensing that aims to learn robust visual features with rich semantics, as well as aligned text embeddings for seamless downstream application. To address the scarcity of pre-training data, we leverage data scaling, converting heterogeneous annotations based on Box-to-Caption (B2C) and Mask-to-Box (M2B) conversion, and further incorporating UAV imagery, resulting a 12xlarger pretraining dataset. RemoteCLIP can be applied to a variety of downstream tasks, including zero-shot image classification, linear probing, k-NN classification, few-shot classification, image-text retrieval, and object counting. Evaluations on 16 datasets, including a newly introduced RemoteCount benchmark to test the object counting ability, show that RemoteCLIP consistently outperforms baseline foundation models across different model scales. Impressively, RemoteCLIP outperform previous SoTA by 9.14% mean recall on RSICD dataset and by 8.92% on RSICD dataset. For zero-shot classification, our RemoteCLIP outperform CLIP baseline by up to 6.39% average accuracy on 12 downstream datasets.