3
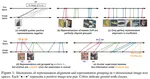
During visual instruction tuning of multi-modal LLM, we introduced a multi-modal response rewriter called “Polite Flamingo” to address the degeneration of response politness, which is a typical instance of the “multi-modal alignment tax”.
Delong Chen, Jianfeng Liu, Wenliang Dai, Baoyuan Wang. “Visual Instruction Tuning with Polite Flamingo”. In AAAI (2024).
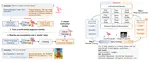
We introduced RemoteCLIP, the first general-purpose vision-language foundation model for remote sensing. RemoteCLIP outperform previous image-text retrieval SoTA by 9.14% mean recall on RSICD dataset and by 8.92% on RSICD dataset. For zero-shot classification, our RemoteCLIP outperform CLIP baseline by up to 6.39% average accuracy on 12 downstream datasets.
Fan Liu, Delong Chen (joint first author), Qingyunguan Zhang et al. “RemoteCLIP: A Vision Language Foundation Model for Remote Sensing”. Arxiv Preprint (2023).

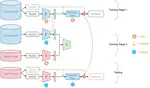
This paper proposed ProtoCLIP for improved representation grouping and enhanced robustness against modality gap in large-scale vision language pretraining. ProtoCLIP improved linear probing and zero-shot accuracy by 5.8% and 2.0%, and matched the performance of CLIP with 3×fewer epochs.
Delong Chen, Zhao Wu, Fan Liu, et al. “ProtoCLIP: Prototypical Contrastive Language Image Pretraining” In IEEE Transactions on Neural Networks and Learning Systems, TNNLS (2023).