Delong Chen (陈德龙) is a PhD student (2023-) at Hong Kong University of Science and Technology (HKUST) under the supervision of Prof. Pascale Fung. He is now working on vision-language and representation learning. He received the B.Eng degree of computer science in 2021 from Hohai University, where he was advised by Prof. Fan Liu. Afterwards, he took two gap years doing internships at MEGVII (Face++) Research, MSRA and Xiaobing.AI (Xiaoice).
He recived Best Demo award at IEEE ICME'21, Best Dataset Paper at LTDL@IJCAI'21, Best Paper in AAAI'23 Inaugural Summer Symposium Series, and First Class Outstanding Thesis of Jiangsu Province. He served as a reviewer for NeurIPS'24, ACL ARR (ACL'24, EMNLP'24), ACM Multimedia'23/24, ACM TIST, IEEE TITS, Artificial Intelligence Review, etc, and volunteered at AAAI-24 and ACL'24.
📄 Download CV (updated on May 2024)
News
▼ 2023
[2023-09-21]. Happy to share the latest work collaborated with Xinyu Zhou (周欣宇) ❤. We study the potential of building a unified spoken-dialogue system based on large language models, thus enabling AI chatbots to “think how to respond” and “think how to speak” at the same time!
Xinyu Zhou, Delong Chen, Yudong Chen
🎙 Towards Joint Modeling of Dialogue Response and Speech Synthesis based on Large Language Model
International Conference on Natural Language and Speech Processing (ICNLSP) 2023. [arxiv] [github]
[2023-07-18]. Our Diffusion-Conductor is awarded as Best Paper in AAAI 2023 Inaugural Summer Symposium Series - AI x Metaverse! The GAN-based Virtual Conductor proposed in my bachelor thesis is now upgraded to its diffusion-based version!
Zhuoran Zhao, Jinbin Bai, Delong Chen, Debang Wang, Yubo Pan
🎶 Taming Diffusion Models for Music-driven Conducting Motion Generation
In AAAI 2023 Inaugural Summer Symposium Series - AI x Metaverse, 2023 (Best Paper). [arxiv] [github]
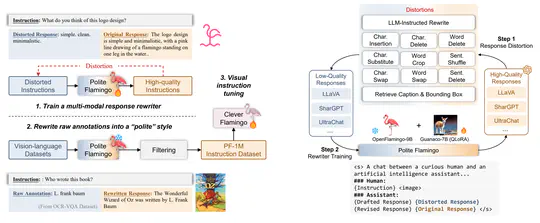
[2023-06-30]. Excited to share my latest work done during my internship at Xiaobing.AI – Polite Flamingo! During visual instruction tuning of multi-modal LLM, we introduced a multi-modal response rewriter to address the degeneration of response politness, which is a typical instance of the “multi-modal alignment tax”. Many thanks my great mentors Baoyuan Wang (王宝元) and Jianfeng Liu (刘剑锋) at Xiaobing.AI, and Wenliang Dai (戴文亮) at HKUST!
Delong Chen, Jianfeng Liu, Wenliang Dai, Baoyuan Wang
🦩 Visual Instruction Tuning with Polite Flamingo
[arxiv] [github] [Demo]
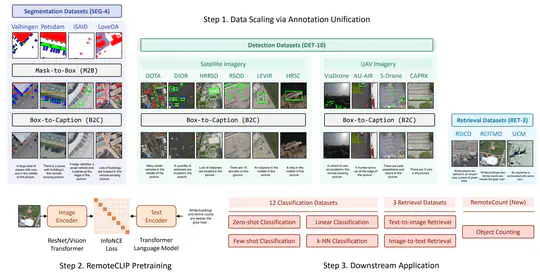
[2023-06-19]. We annonce RemoteCLIP, the first vision-language foundation model for remote sensing. RemoteCLIP outperform previous image-text retrieval SoTA by 9.14% mean recall on RSICD dataset and by 8.92% on RSICD dataset. For zero-shot classification, our RemoteCLIP outperform CLIP baseline by up to 6.39% average accuracy on 12 downstream datasets. This is a team work with many brilliant grad students at AIM Group, thanks Zhangqingyun Guan (管张青云), Xiaocong Zhou (周晓聪), Jiale Zhu (朱佳乐), and Wenwen Cai (蔡雯雯)!
Fan Liu, Delong Chen (joint first author), Zhangqingyun Guan, Xiaocong Zhou, Jiale Zhu, Jun Zhou
🛰️ RemoteCLIP: Vision-Language Pretraining for Remote Sensing
[arxiv] [github]
[2023-04-22]. Our paper of Ensemble Learning with Multi-Order Statistics (ELMOS) is accepted by IJCAI-23 as oral presentation! Our proposed model achieves SoTA few-shot classification accuracy on CUB dataset, miniImageNet, tiredImageNet, and CIFAR-FS dataset.
Sai Yang, Fan Liu, Delong Chen, Jun Zhou
🔍 Few-shot Classification via Ensemble Learning with Multi-Order Statistics
In Proceedings of the 32nd IJCAI, 2023 (oral). [arxiv]
[2023-03-11]. Our works on the Multi-modal E-Commerce Products (MEP-3M) dataset, previously awarded as IJCAI 2021 LTDL Best Dataset Paper, is now extended and published at Pattern Recognition.
Fan Liu, Delong Chen (joint first author), Xiaoyu Du, Ruizhuo Gao, Feng Xu
🎁 MEP-3M: A large-scale multi-modal E-commerce product dataset
Pattern Recognition, 2023.
▶ 2022
[2022-07-08]. Our survey paper on Deep Learning Based Single Sample Per Person (SSPP) face recognition is now published in Artificial Intelligence Review (IF=12.0).
Fan Liu, Delong Chen (joint first author), Fei Wang, Zewen Li, Feng Xu
🤖 Deep learning based single sample face recognition: a survey
Artificial Intelligence Review, 2022
[2022-06-29]. My bachelor graduation thesis “Music-driven Conducting Motion Generation based on Motion Decomposition and Self-supervised Cross-modal Perceptual Loss” 《基于动态频域分解与跨模态感知的乐队指挥动作生成系统》, previously awarded as Outstanding Graduation Thesis of HHU (河海大学优秀毕业论文), is now awarded as the First Class of Outstanding Graduation Thesis of Jiangsu Province (江苏省优秀毕业论文一等奖) !
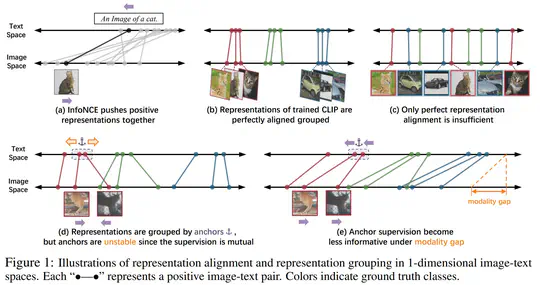
[2022-06-23]. Our work on ProtoCILP is done at Megvii Technology. We developed a prototype-based approach for improved vision language pretraining, which achieved an +5.81% ImageNet linear probing improvement and an +2.01% ImageNet zero-shot classification improvement compared to CLIP.
Delong Chen, Zhao Wu, Fan Liu, Zaiquan Yang, Yixiang Huang, Yiping Bao, Erjin Zhou
📍 ProtoCILP: Prototypical Contrastive Language Image Pretraining
arXiv preprint, 2022. [arxiv] [github]
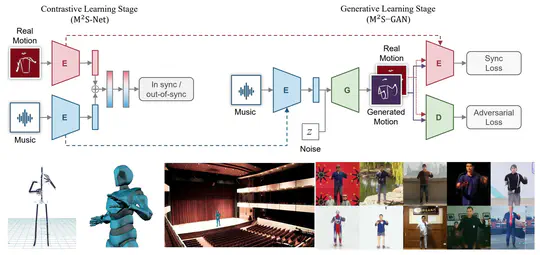
[2022-03-10]. Our paper on Music-Driven Conducting Motion Generation is accepted by CCF-B journal JCST. The ConductorMotion100 dataset has been made public as a track of The 1st Prospective Cup Meta-Intelligent Data Challenge(首届国际“远见杯”元智能数据挑战大赛)hold by Jiangsu Computer Society(江苏省计算机学会).
Fan Liu, Delong Chen (✉), Ruizhi Zhou, Sai Yang, Feng Xu
🎵 Self-Supervised Music Motion Synchronization Learning for Music-Driven Conducting Motion Generation
In Journal of Computer Science and Technology (JCST), 2022. [github] [video]
▶ 2021
[2021-09-22]. I begin to work at MEGVII Technology (旷视研究院) as a research intern with Yiping Bao (鲍一平) and Zhao Wu (吴曌).
[2021-08-21]. I received a Best Demo Award from IEEE ICME'21, a Best Dataset Paper Award from IJCAI'21 LTDL workshop, and a Best Presentation Award from IEEE BDAI'21.
Delong Chen, Fan Liu, Zewen Li, Feng Xu
🎵 VirtualConductor: Music-driven Conducting Video Generation System
In IEEE International Conference on Multimedia and Expo (ICME) 2021 (Best Demo Award). [arxiv] [video]
Delong Chen, Fan Liu, Xiaoyu Du, Ruizhuo Gao, Feng Xu
🎁 MEP-3M: A Large-scale Multi-modal E-Commerce Products Dataset
In IJCAI 2021 Workshop on Long-Tailed Distribution Learning (LTDL@IJCAI'21) (Best Dataset Paper Award).
Delong Chen, Fan Liu, Zheqi Zhang, Xiaomin Lu, Zewen Li
🌊 Significant Wave Height Prediction based on Wavelet Graph Neural Network
In 2021 IEEE 4th International Conference on Big Data and Artificial Intelligence (Best Presentation). [arxiv]
[1999-03-19]. I was born in Shunde, Guangdong(广东,顺德), a beautiful city with a lot of delicious food.
Selected Publications ⭐
During visual instruction tuning of multi-modal LLM, we introduced a multi-modal response rewriter called “Polite Flamingo” to address the degeneration of response politness, which is a typical instance of the “multi-modal alignment tax”.
Delong Chen, Jianfeng Liu, Wenliang Dai, Baoyuan Wang. “Visual Instruction Tuning with Polite Flamingo”. In AAAI (2024).
We introduced RemoteCLIP, the first general-purpose vision-language foundation model for remote sensing. RemoteCLIP outperform previous image-text retrieval SoTA by 9.14% mean recall on RSICD dataset and by 8.92% on RSICD dataset. For zero-shot classification, our RemoteCLIP outperform CLIP baseline by up to 6.39% average accuracy on 12 downstream datasets.
Fan Liu, Delong Chen (joint first author), Qingyunguan Zhang et al. “RemoteCLIP: A Vision Language Foundation Model for Remote Sensing”. Arxiv Preprint (2023).
We construct a large-scale Multi-modal E-commerce Products classification dataset MEP-3M, which consists of over 3 million products and 599 fine-grained product categories. Previsouly, the conference version of this paper won IJCAI 2021 LTDL Best Dataset Paper award.
Fan Liu, Delong Chen (joint first author), Xiaoyu Du, et al. “MEP-3M: A Large-scale Multi-modal E-Commerce Products Dataset”. In Pattern Recognition (2023).

This paper proposed ProtoCLIP for improved representation grouping and enhanced robustness against modality gap in large-scale vision language pretraining. ProtoCLIP improved linear probing and zero-shot accuracy by 5.8% and 2.0%, and matched the performance of CLIP with 3×fewer epochs.
Delong Chen, Zhao Wu, Fan Liu, et al. “ProtoCLIP: Prototypical Contrastive Language Image Pretraining” In IEEE Transactions on Neural Networks and Learning Systems, TNNLS (2023).
This paper proposed the first deep-learning based music-driven conducting motion generation method, and presented a large-scale music motion dataset ConductorMotion100 with unprecedented 100 hours length. The associated demo paper won the Best Demo Award in IEEE ICME 2021. My graduation thesis at HHU on this project was awarded as “First Class of Outstanding Graduation Thesis of Jiangsu Province” (江苏省优秀本科毕业论文一等奖).
Fan Liu, Delong Chen (corresponding author), et al. “Self-Supervised Music Motion Synchronization Learning for Music-Driven Conducting Motion Generation”. In Journal of Computer Science Technology, JCST (2022).
Experience 🎓
- In Center for Artificial Intelligence Research (CAiRE). Supervisor: Prof. Pascale Fung (冯雁)
Research Projects:
- Visual Instruction Tuning with Polite Flamingo. arXiv Preprint.
- Instruct Flamingo: Codebase and Fondation Models for Visual Instruction Tuning. Open Source Project.
- Taming Diffusion Models for Music-driven Conducting Motion Generation. AAAI 2023 Inaugural Summer Symposium Series - AI x Metaverse (Best Paper).
Mentors: Baoyuan Wang (王宝元), Jianfeng Liu (刘剑锋)
Vision-language Learning:
- RemoteCLIP: A Vision Language Foundation Model for Remote Sensing. arXiv Preprint.
- MEP-3M: A Large-scale Multi-modal E-Commerce Products Dataset. Pattern Recognition.
Few-shot Learning:
- Few-shot classification guided by generalization error bound. Pattern Recognition.
- Few-shot Classification via Ensemble Learning with Multi-Order Statistics. IJCAI-23 (oral).
AI for Hydro-Science:
- A Simple Baseline for Adversarial Domain Adaptation-based Unsupervised Flood Forecasting. arXiv Preprint.
- Asymmetric exponential loss function for crack segmentation. Multimedia Systems.
- Significant Wave Height Prediction based on Wavelet Graph Neural Network. IEEE BDAI 2021.
Face Recogniztion and Analysis:
- Deep Learning based Single Sample Face Recognition: a Survey. Artificial Intelligence Review.
- A Review of Driver Fatigue Detection and Its Advances on the Use of RGB-D Camera and Deep Learning. Engineering Applications of Artificial Intelligence.
Supervisor: Prof. Fan Liu(刘凡)
Courses:
- Computation for Natural Language Processing (scored 97/100)
- Linguistics for Natural Language Processing (scored 85/100)
Thesis Project:
- 《基于动态频域分解与跨模态感知的乐队指挥动作生成系统》. 河海大学优秀毕业论文, 江苏省优秀本科毕业论文一等奖. (Outstanding Graduation Thesis of HHU, First-class Outstanding Graduation Thesis of Jiangsu Province)
- VirtualConductor: Music-driven Conducting Video Generation System. ICME 2021 (Best Demo Award).
- Self-Supervised Music Motion Synchronization Learning for Music-Driven Conducting Motion Generation. Journal of Computer Science and Technology.
Awards✨
- 2023-01. Best Paper Award at AAAI 2023 Inaugural Summer Symposium Series - AI x Metaverse
- 2022-06. 江苏省优秀本科毕业论文一等奖 First Class Outstanding Graduation Thesis of Jiangsu Province
- 2021-08. Best Dataset Paper Award at Long-Tailed Distribution Learning Workshop, IJCAI 2021
- 2021-07. Best Demo Award at IEEE International Conference on Multimedia and Expo (ICME) 2021
- 2021-07. Best Presentation Winner at 2021 4th International Conference on Big Data and Artificial Intelligence
- 2021-06. 河海大学2021届本科优秀毕业设计 Outstanding Graduation Thesis of Hohai University in 2021
- 2021-06. 河海大学2021届本科“优秀毕业生”荣誉称号 Excellent Graduate Student of Hohai University (highest honor)
- 2021-04. 2020江苏省大学生网络文化节校园歌曲作品征集一等奖 First Prize in 2020 Campus Music Competition of Jiangsu Province
- 2020-05. “江苏省优秀共青团员”称号 Excellent Communist Youth League Member of Jiangsu Province
- 2020-10. “2019江苏省大学生年度人物”提名奖 Nomination Award for the Person of the Year in Jiangsu Province in 2019
- 2020-04. 2020年河海大学“海韵风华大学生年度人物”称号 Hohai University 2019 Undergraduate Person of the Year
- 2019-06. 第八届“中国软件杯”大学生软件设计大赛华东分赛区决赛三等奖 (团队负责人) Third Prize of The 8th China Software Cup (East China Division Finals)
- 2017-10. 河海大学计算机与信息学院2017年新生杯辩论赛“最佳辩手”称号 Best Debater in the 2017 Freshman Cup Debate Competition at Hohai University
Music 🎻




🐎 敢 杀 我 的 马 ?!(小提琴协奏曲)
Remixed violin concerto of “Dare You Kill My Horse”. 400k views on Bilibili.

11校云合奏《汉阳门花园》
Cloud Symphony: Hanyang Gate Garden. Organized an 11-university symphony orchestra cloud performance – composition, audio mixing, and video editing. Media coverage Xinhua News Agency (新华社), People’s Daily (人民日报)
Gallery 📸